Spark
https://databricks.com/blog
基本概念 RDD特点 RDD具有容错机制,并且只读不能修改,RDD具有以下几个属性:
只读:不能修改,只能通过转换操作生成新的RDD
分布式:可以分布在多台机器上进行并行处理
弹性:计算过程中内存不够时会和磁盘进行数据交换
基于内存:可以全部或部分缓存在内存中,在多次计算间重用
RDD血缘关系 RDD 的最重要的特性之一就是血缘关系(Lineage ),它描述了一个 RDD 是如何从父 RDD 计算得来的。如果某个 RDD 丢失了,则可以根据血缘关系,从父 RDD 计算得来。
RDD依赖类型 根据不同的转换操作,RDD血缘关系的依赖分为宽依赖和窄依赖。窄依赖是指父RDD的每个分区都只被子RDD的一个分区使用。宽依赖是指父RDD的每个分区都被子RDD的分区所依赖。
Spark启动流程 org.apache.spark.deploy.SparkSubmit.main
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private [deploy] def prepareSubmitEnvironment args: SparkSubmitArguments , conf: Option [HadoopConfiguration ] = None ) : (Seq [String ], Seq [String ], SparkConf , String ){ ... if (isYarnCluster) { childMainClass = YARN_CLUSTER_SUBMIT_CLASS # org.apache.spark.deploy.yarn.YarnClusterApplication if (args.isPython) { childArgs += ("--primary-py-file" , args.primaryResource) childArgs += ("--class" , "org.apache.spark.deploy.PythonRunner" ) } else if (args.isR) { val mainFile = new Path (args.primaryResource).getName childArgs += ("--primary-r-file" , mainFile) childArgs += ("--class" , "org.apache.spark.deploy.RRunner" ) } else { if (args.primaryResource != SparkLauncher .NO_RESOURCE ) { childArgs += ("--jar" , args.primaryResource) } childArgs += ("--class" , args.mainClass) } if (args.childArgs != null ) { args.childArgs.foreach { arg => childArgs += ("--arg" , arg) } } } }
org.apache.spark.deploy.yarn.Client内部类
org.apache.spark.deploy.yarn.YarnClusterApplication
1 2 3 4 5 6 7 8 9 10 11 12 private [spark] class YarnClusterApplication extends SparkApplication override def start Array [String ], conf: SparkConf ): Unit = { conf.remove(JARS ) conf.remove(FILES ) new Client (new ClientArguments (args), conf, null ).run() } }
org.apache.spark.deploy.yarn.Client
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 private [spark] class Client ( val args: ClientArguments , val sparkConf: SparkConf , val rpcEnv: RpcEnv ) extends Logging def run Unit = { this .appId = submitApplication() if (!launcherBackend.isConnected() && fireAndForget) { val report = getApplicationReport(appId) val state = report.getYarnApplicationState logInfo(s"Application report for $appId (state: $state )" ) logInfo(formatReportDetails(report)) if (state == YarnApplicationState .FAILED || state == YarnApplicationState .KILLED ) { throw new SparkException (s"Application $appId finished with status: $state " ) } } else { val YarnAppReport (appState, finalState, diags) = monitorApplication(appId) if (appState == YarnApplicationState .FAILED || finalState == FinalApplicationStatus .FAILED ) { diags.foreach { err => logError(s"Application diagnostics message: $err " ) } throw new SparkException (s"Application $appId finished with failed status" ) } if (appState == YarnApplicationState .KILLED || finalState == FinalApplicationStatus .KILLED ) { throw new SparkException (s"Application $appId is killed" ) } if (finalState == FinalApplicationStatus .UNDEFINED ) { throw new SparkException (s"The final status of application $appId is undefined" ) } } } def submitApplication ApplicationId = { ResourceRequestHelper .validateResources(sparkConf) var appId: ApplicationId = null try { launcherBackend.connect() yarnClient.init(hadoopConf) yarnClient.start() logInfo("Requesting a new application from cluster with %d NodeManagers" .format(yarnClient.getYarnClusterMetrics.getNumNodeManagers)) val newApp = yarnClient.createApplication() val newAppResponse = newApp.getNewApplicationResponse() appId = newAppResponse.getApplicationId() val appStagingBaseDir = sparkConf.get(STAGING_DIR ) .map { new Path (_, UserGroupInformation .getCurrentUser.getShortUserName) } .getOrElse(FileSystem .get(hadoopConf).getHomeDirectory()) stagingDirPath = new Path (appStagingBaseDir, getAppStagingDir(appId)) new CallerContext ("CLIENT" , sparkConf.get(APP_CALLER_CONTEXT ), Option (appId.toString)).setCurrentContext() verifyClusterResources(newAppResponse) val containerContext = createContainerLaunchContext(newAppResponse) val appContext = createApplicationSubmissionContext(newApp, containerContext) logInfo(s"Submitting application $appId to ResourceManager" ) yarnClient.submitApplication(appContext) launcherBackend.setAppId(appId.toString) reportLauncherState(SparkAppHandle .State .SUBMITTED ) appId } catch { case e: Throwable => if (stagingDirPath != null ) { cleanupStagingDir() } throw e } } }
SparkContext初始化
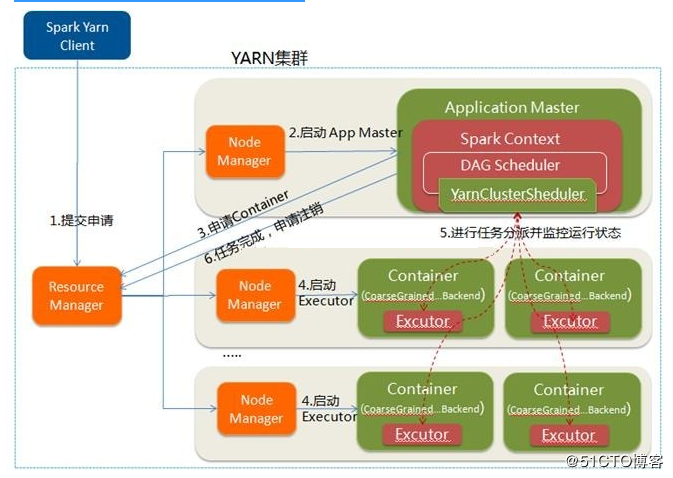
yarn-cluster 模式下:client会先申请向RM(Yarn Resource Manager)一个Container,来启动AM(ApplicationMaster)进程,而SparkContext运行在AM(ApplicationMaster)进程中;
yarn-client 模式下:在提交节点上执行SparkContext初始化,由client类(JavaMainApplication)调用。
1 2 3 4 5 6 7 8 9 10 11 12 ... val (sched, ts) = SparkContext .createTaskScheduler(this , master, deployMode)_schedulerBackend = sched _taskScheduler = ts _dagScheduler = new DAGScheduler (this ) _taskScheduler.start() ...
1、SparkSubmit
封装参数
准备部署环境
利用反射执行部署类(Client)
2、YarnClient
3、ApplicationMaster
封装参数
启动Driver线程,执行用户程序(runDriver)
向RM注册并申请资源
获取资源后,启动ExecutorBackend
4、ExecutorBackend
start方法:向Driver注册
receive方法:创建Executor对象
重要组件 BlockManager TODO:
Spark Listener
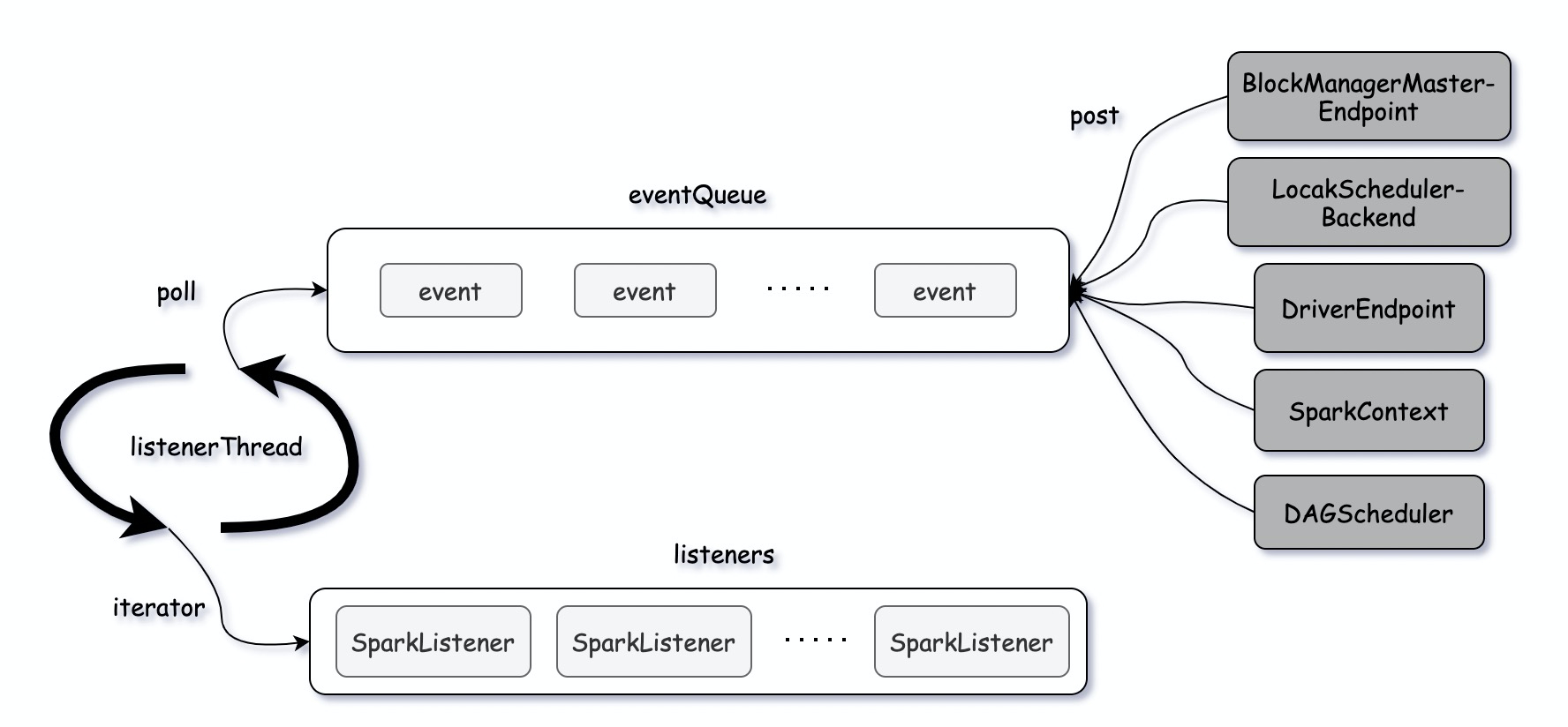
初始化SparkContext的时候初始化LiveListenerBus
一个LiveListenerBus包含多个queue (AsyncEventQueue)
后面会调用 setupAndStartListenerBus 方法,启动queue ,并把event 放到queue 中
AsyncEventQueue.dispatch启动后,循环调用postToAll 方法,把阻塞队列里的event 发送给listener
SparkContext 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ... _listenerBus = new LiveListenerBus (_conf) ... setupAndStartListenerBus() ... private def setupAndStartListenerBus Unit = { try { conf.get(EXTRA_LISTENERS ).foreach { classNames => val listeners = Utils .loadExtensions(classOf[SparkListenerInterface ], classNames, conf) listeners.foreach { listener => listenerBus.addToSharedQueue(listener) logInfo(s"Registered listener ${listener.getClass().getName()} " ) } } } catch { case e: Exception => try { stop() } finally { throw new SparkException (s"Exception when registering SparkListener" , e) } } listenerBus.start(this , _env.metricsSystem) _listenerBusStarted = true }
LiveListenerBus 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ... private val queues = new CopyOnWriteArrayList [AsyncEventQueue ]()@volatile private [scheduler] var queuedEvents = new mutable.ListBuffer [SparkListenerEvent ]()... def start SparkContext , metricsSystem: MetricsSystem ): Unit = synchronized { if (!started.compareAndSet(false , true )) { throw new IllegalStateException ("LiveListenerBus already started." ) } this .sparkContext = sc queues.asScala.foreach { q => q.start(sc) queuedEvents.foreach(q.post) } queuedEvents = null metricsSystem.registerSource(metrics) }
AsyncEventQueue 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private def dispatch Unit = LiveListenerBus .withinListenerThread.withValue(true ) { var next: SparkListenerEvent = eventQueue.take() while (next != POISON_PILL ) { val ctx = processingTime.time() try { super .postToAll(next) } finally { ctx.stop() } eventCount.decrementAndGet() next = eventQueue.take() } eventCount.decrementAndGet() }
Spark 内存
https://mp.weixin.qq.com/s/xTWAPtgUc5hZMxxKitD-MQ