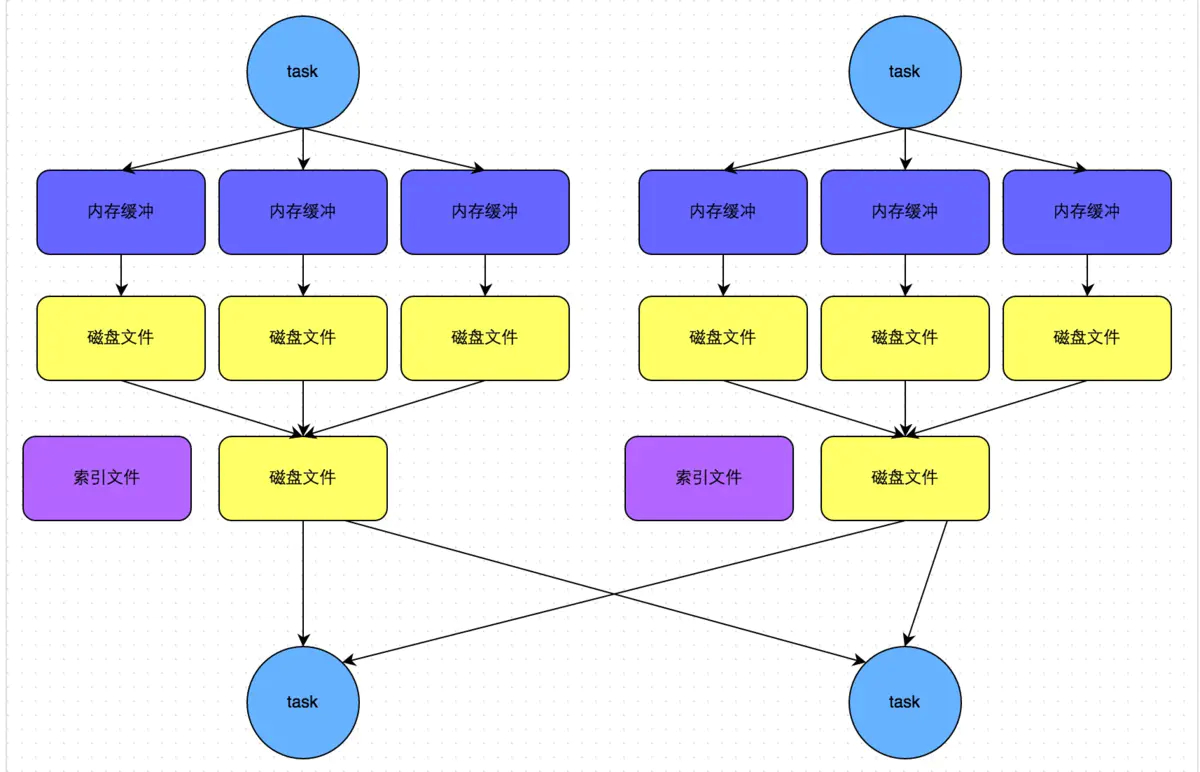
... // Let the user specify short names for shuffle managers val shortShuffleMgrNames = Map( "sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName, "tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName) val shuffleMgrName = conf.get("spark.shuffle.manager", "sort") val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName) val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass) ...
@Override publicvoidwrite(Iterator<Product2<K, V>> records)throws IOException { assert (partitionWriters == null); ShuffleMapOutputWriter mapOutputWriter = shuffleExecutorComponents .createMapOutputWriter(shuffleId, mapId, numPartitions); try { if (!records.hasNext()) { // 没有数据则输出一个空文件 partitionLengths = mapOutputWriter.commitAllPartitions().getPartitionLengths(); mapStatus = MapStatus$.MODULE$.apply( blockManager.shuffleServerId(), partitionLengths, mapId); return; } final SerializerInstance serInstance = serializer.newInstance(); finallong openStartTime = System.nanoTime(); partitionWriters = new DiskBlockObjectWriter[numPartitions]; partitionWriterSegments = new FileSegment[numPartitions]; for (int i = 0; i < numPartitions; i++) { final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile = blockManager.diskBlockManager().createTempShuffleBlock(); final File file = tempShuffleBlockIdPlusFile._2(); final BlockId blockId = tempShuffleBlockIdPlusFile._1(); partitionWriters[i] = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics); } // Creating the file to write to and creating a disk writer both involve interacting with // the disk, and can take a long time in aggregate when we open many files, so should be // included in the shuffle write time. writeMetrics.incWriteTime(System.nanoTime() - openStartTime);
while (records.hasNext()) { final Product2<K, V> record = records.next(); final K key = record._1(); // 如果有数据,按key对应的分区,分别写入对应的文件 partitionWriters[partitioner.getPartition(key)].write(key, record._2()); }
for (int i = 0; i < numPartitions; i++) { try (DiskBlockObjectWriter writer = partitionWriters[i]) { partitionWriterSegments[i] = writer.commitAndGet(); } } // 将多个分区文件合并成一个文件,并生成索引文件 partitionLengths = writePartitionedData(mapOutputWriter); mapStatus = MapStatus$.MODULE$.apply( blockManager.shuffleServerId(), partitionLengths, mapId); } catch (Exception e) { try { mapOutputWriter.abort(e); } catch (Exception e2) { logger.error("Failed to abort the writer after failing to write map output.", e2); e.addSuppressed(e2); } throw e; } }
/** * Concatenate all of the per-partition files into a single combined file. * * @return array of lengths, in bytes, of each partition of the file (used by map output tracker). */ privatelong[] writePartitionedData(ShuffleMapOutputWriter mapOutputWriter) throws IOException { // Track location of the partition starts in the output file if (partitionWriters != null) { finallong writeStartTime = System.nanoTime(); try { for (int i = 0; i < numPartitions; i++) { final File file = partitionWriterSegments[i].file(); ShufflePartitionWriter writer = mapOutputWriter.getPartitionWriter(i); if (file.exists()) { if (transferToEnabled) { // Using WritableByteChannelWrapper to make resource closing consistent between // this implementation and UnsafeShuffleWriter. Optional<WritableByteChannelWrapper> maybeOutputChannel = writer.openChannelWrapper(); if (maybeOutputChannel.isPresent()) { writePartitionedDataWithChannel(file, maybeOutputChannel.get()); } else { writePartitionedDataWithStream(file, writer); } } else { writePartitionedDataWithStream(file, writer); } if (!file.delete()) { logger.error("Unable to delete file for partition {}", i); } } } } finally { writeMetrics.incWriteTime(System.nanoTime() - writeStartTime); } partitionWriters = null; } // 生成 index文件 return mapOutputWriter.commitAllPartitions(); }
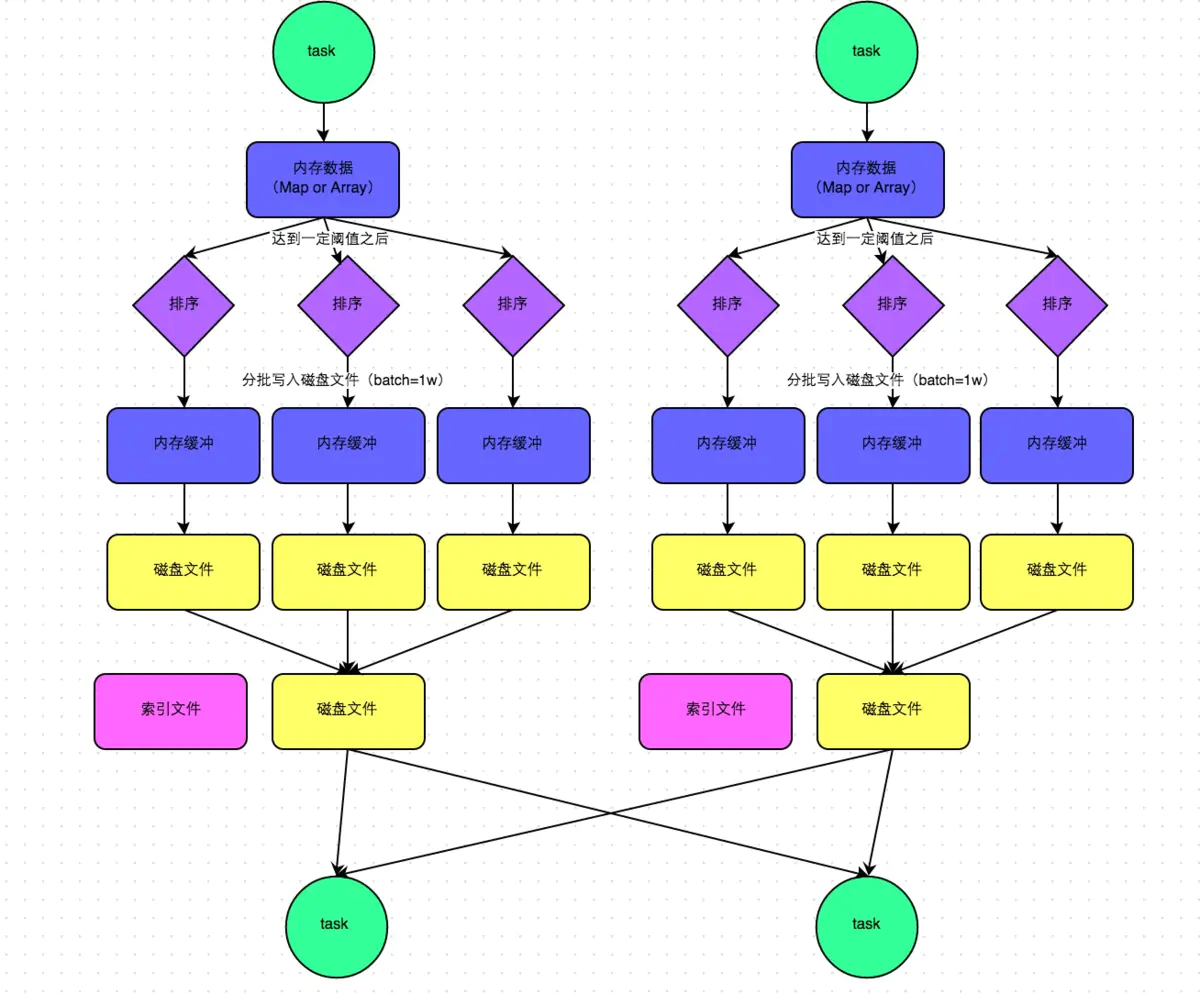
overridedefwrite(records: Iterator[Product2[K, V]]): Unit = { sorter = if (dep.mapSideCombine) { // map端需要聚合,选择PartitionedAppendOnlyMap newExternalSorter[K, V, C]( context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer) } else { // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't // care whether the keys get sorted in each partition; that will be done on the reduce side // if the operation being run is sortByKey. // mao端不需要聚合选择PartitionedPairBuffer newExternalSorter[K, V, V]( context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer) } sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time, // because it just opens a single file, so is typically too fast to measure accurately // (see SPARK-3570). val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId) val tmp = Utils.tempFileWith(output) try { val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID) val partitionLengths = sorter.writePartitionedFile(blockId, tmp) // 生成索引文件 shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp) mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths) } finally { if (tmp.exists() && !tmp.delete()) { logError(s"Error while deleting temp file ${tmp.getAbsolutePath}") } } }
definsertAll(records: Iterator[Product2[K, V]]): Unit = { // TODO: stop combining if we find that the reduction factor isn't high val shouldCombine = aggregator.isDefined
if (shouldCombine) { // Combine values in-memory first using our AppendOnlyMap val mergeValue = aggregator.get.mergeValue val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null val update = (hadValue: Boolean, oldValue: C) => { if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { addElementsRead() kv = records.next() // 第一次预聚合 map.changeValue((getPartition(kv._1), kv._1), update) // 判断是否需要spill maybeSpillCollection(usingMap = true) } } else { // Stick values into our buffer while (records.hasNext) { addElementsRead() val kv = records.next() buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) maybeSpillCollection(usingMap = false) } } }
/** * Spill the current in-memory collection to disk if needed. * * @param usingMap whether we're using a map or buffer as our current in-memory collection */ privatedefmaybeSpillCollection(usingMap: Boolean): Unit = { var estimatedSize = 0L if (usingMap) { estimatedSize = map.estimateSize() // maybeSpill方法为spill的实现(org.apache.spark.util.collection.Spillable) if (maybeSpill(map, estimatedSize)) { map = newPartitionedAppendOnlyMap[K, C] } } else { estimatedSize = buffer.estimateSize() if (maybeSpill(buffer, estimatedSize)) { buffer = newPartitionedPairBuffer[K, C] } }
if (estimatedSize > _peakMemoryUsedBytes) { _peakMemoryUsedBytes = estimatedSize } }
/** * Spill our in-memory collection to a sorted file that we can merge later. * We add this file into `spilledFiles` to find it later. * * @param collection whichever collection we're using (map or buffer) */ overrideprotected[this] defspill(collection: WritablePartitionedPairCollection[K, C]): Unit = { // 调用AppendOnlyMap.destructiveSortedWritablePartitionedIterator 进行内存排序 val inMemoryIterator = collection.destructiveSortedWritablePartitionedIterator(comparator) val spillFile = spillMemoryIteratorToDisk(inMemoryIterator) spills += spillFile }
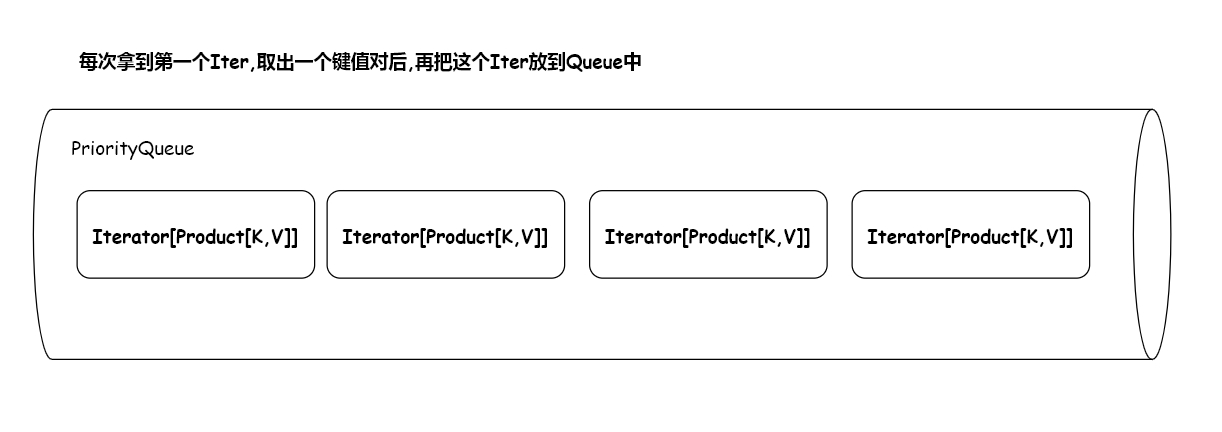
/** * Merge-sort a sequence of (K, C) iterators using a given a comparator for the keys. */ privatedefmergeSort(iterators: Seq[Iterator[Product2[K, C]]], comparator: Comparator[K]) : Iterator[Product2[K, C]] ={ { val bufferedIters = iterators.filter(_.hasNext).map(_.buffered) typeIter= BufferedIterator[Product2[K, C]] val heap = new mutable.PriorityQueue[Iter]()(newOrdering[Iter] { // Use the reverse order because PriorityQueue dequeues the max overridedefcompare(x: Iter, y: Iter): Int = comparator.compare(y.head._1, x.head._1) }) // 放到优先级队列 heap.enqueue(bufferedIters: _*) // Will contain only the iterators with hasNext = true newIterator[Product2[K, C]] { overridedefhasNext: Boolean = !heap.isEmpty
overridedefnext(): Product2[K, C] = { if (!hasNext) { thrownewNoSuchElementException } val firstBuf = heap.dequeue() val firstPair = firstBuf.next() if (firstBuf.hasNext) { // 取完后放回到队列中 heap.enqueue(firstBuf) } firstPair } } } // 第二次预聚合 privatedefmergeWithAggregation( iterators: Seq[Iterator[Product2[K, C]]], mergeCombiners: (C, C) => C, comparator: Comparator[K], totalOrder: Boolean) : Iterator[Product2[K, C]] = { if (!totalOrder) { ... } else { // We have a total ordering, so the objects with the same key are sequential. newIterator[Product2[K, C]] { // 获取优先级队列 sorted val sorted = mergeSort(iterators, comparator).buffered overridedefhasNext: Boolean = sorted.hasNext overridedefnext(): Product2[K, C] = { if (!hasNext) { thrownewNoSuchElementException } // 先取出一个键值对 val elem = sorted.next() val k = elem._1 var c = elem._2 // 比较 k 是否相等 while (sorted.hasNext && sorted.head._1 == k) { val pair = sorted.next() // 如果相等就合并 c = mergeCombiners(c, pair._2) } (k, c) } } } }
// 把key和value存在同一数组中 // Holds keys and values in the same array for memory locality; specifically, the order of // elements is key0, value0, key1, value1, key2, value2, etc. privatevar data = newArray[AnyRef](2 * capacity)
// 内存排序 /** * Return an iterator of the map in sorted order. This provides a way to sort the map without * using additional memory, at the expense of destroying the validity of the map. */ defdestructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = { destroyed = true // Pack KV pairs into the front of the underlying array var keyIndex, newIndex = 0 // 把不为null的KV对移到数组最前面 while (keyIndex < capacity) { if (data(2 * keyIndex) != null) { data(2 * newIndex) = data(2 * keyIndex) data(2 * newIndex + 1) = data(2 * keyIndex + 1) newIndex += 1 } keyIndex += 1 } assert(curSize == newIndex + (if (haveNullValue) 1else0)) // 内存排序 newSorter(newKVArraySortDataFormat[K, AnyRef]).sort(data, 0, newIndex, keyComparator)
newIterator[(K, V)] { var i = 0 var nullValueReady = haveNullValue defhasNext: Boolean = (i < newIndex || nullValueReady) defnext(): (K, V) = { if (nullValueReady) { nullValueReady = false (null.asInstanceOf[K], nullValue) } else { val item = (data(2 * i).asInstanceOf[K], data(2 * i + 1).asInstanceOf[V]) i += 1 item } } } } // updateFunc: 查看对应的key是否有值,如果有值,把旧值和传入的值合并;如果没值,传入的值作为初始值 // 更新数组中的键值对 defchangeValue(key: K, updateFunc: (Boolean, V) => V): V = { assert(!destroyed, destructionMessage) val k = key.asInstanceOf[AnyRef] if (k.eq(null)) { if (!haveNullValue) { incrementSize() } // 内存合并值 nullValue = updateFunc(haveNullValue, nullValue) haveNullValue = true return nullValue } // 重新hash var pos = rehash(k.hashCode) & mask var i = 1 while (true) { // 从data数组中计算出当前key val curKey = data(2 * pos) if (curKey.eq(null)) { // 内存合并值 val newValue = updateFunc(false, null.asInstanceOf[V]) data(2 * pos) = k data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] incrementSize() return newValue } elseif (k.eq(curKey) || k.equals(curKey)) { // 内存合并值 val newValue = updateFunc(true, data(2 * pos + 1).asInstanceOf[V]) data(2 * pos + 1) = newValue.asInstanceOf[AnyRef] return newValue } else { val delta = i pos = (pos + delta) & mask i += 1 } } null.asInstanceOf[V] // Never reached but needed to keep compiler happy }
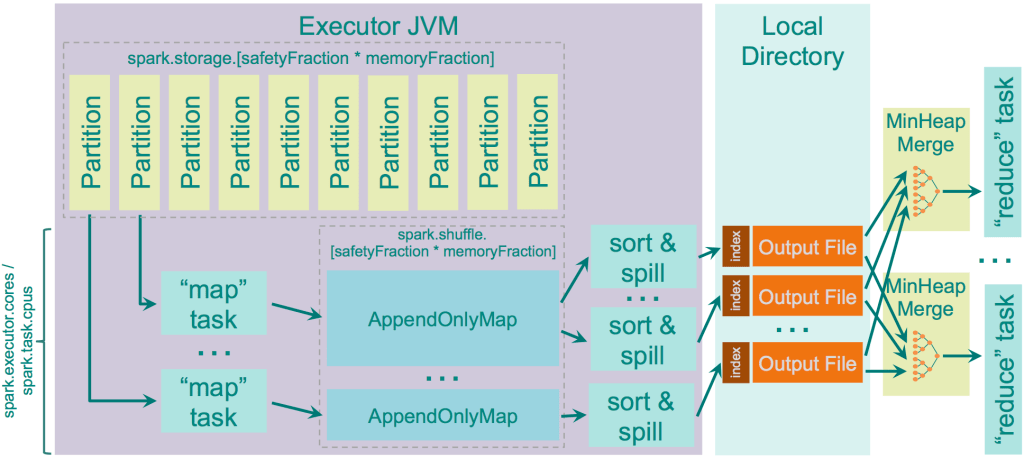
// 设置spill阈值 private[this] val initialMemoryThreshold: Long = SparkEnv.get.conf.getLong("spark.shuffle.spill.initialMemoryThreshold", 5 * 1024 * 1024) // spark.shuffle.spill.numElementsForceSpillThreshold private[this] val numElementsForceSpillThreshold: Int = SparkEnv.get.conf.get(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD)
protecteddefspill(collection: C): Unit
/** * Spills the current in-memory collection to disk if needed. Attempts to acquire more * memory before spilling. * * @param collection collection to spill to disk * @param currentMemory estimated size of the collection in bytes * @return true if `collection` was spilled to disk; false otherwise */ protecteddefmaybeSpill(collection: C, currentMemory: Long): Boolean = { var shouldSpill = false // element个数与32取模是否等于0,判断当前内存字节数是否超过阈值 if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { // Claim up to double our current memory from the shuffle memory pool // 先试着申请2倍的内存(amountToRequest 可能为负数) val amountToRequest = 2 * currentMemory - myMemoryThreshold // 向TaskMemoryManager申请内存 // TaskMemoryManager返回申请到的内存 与 请求的内存比较,如果小于请求的内存,执行如下步骤: // 1、TaskMemoryManager 先释放掉其他consumer的内存(主要是为了减少spill的频率,避免产生过多的spill文件) // 按所有consumer的使用内存进行从小到大排序,取这个map中有没有正好释放掉当前使用的内存的consumer,如果有, // 2、拿到这个符合条件的consumer,进行spill;如果没有,取使用内存最大的consumer,进行spill;循环调用,直至满足申请的内存; // 3、若调用完所有consumer后还没有足够的内存,则调用当前的consumer进行spill val granted = acquireMemory(amountToRequest) myMemoryThreshold += granted // If we were granted too little memory to grow further (either tryToAcquire returned 0, // or we already had more memory than myMemoryThreshold), spill the current collection // 如果授予我们的内存太少而无法进一步增长(tryToAcquire返回0,或内存已经比myMemoryThreshold多),溢出当前集合 shouldSpill = currentMemory >= myMemoryThreshold } // 判断条件 shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold // Actually spill if (shouldSpill) { _spillCount += 1 logSpillage(currentMemory) // ExternalSorter.spill的实现(或 ExternalAppendOnlyMap.spill) spill(collection) _elementsRead = 0 _memoryBytesSpilled += currentMemory releaseMemory() } shouldSpill }
@NullableprivateShuffleExternalSorter sorter; @Override public void write(scala.collection.Iterator<Product2<K, V>> records) throwsIOException { // Keep track of success so we know if we encountered an exception // We do this rather than a standard try/catch/re-throw to handle // generic throwables. boolean success = false; try { while (records.hasNext()) { // 插入sort insertRecordIntoSorter(records.next()); } // 溢出文件合并为一个文件 closeAndWriteOutput(); success = true; } finally { if (sorter != null) { try { sorter.cleanupResources(); } catch (Exception e) { // Only throw this error if we won't be masking another // error. if (success) { throw e; } else { logger.error("In addition to a failure during writing, we failed during " + "cleanup.", e); } } } } }
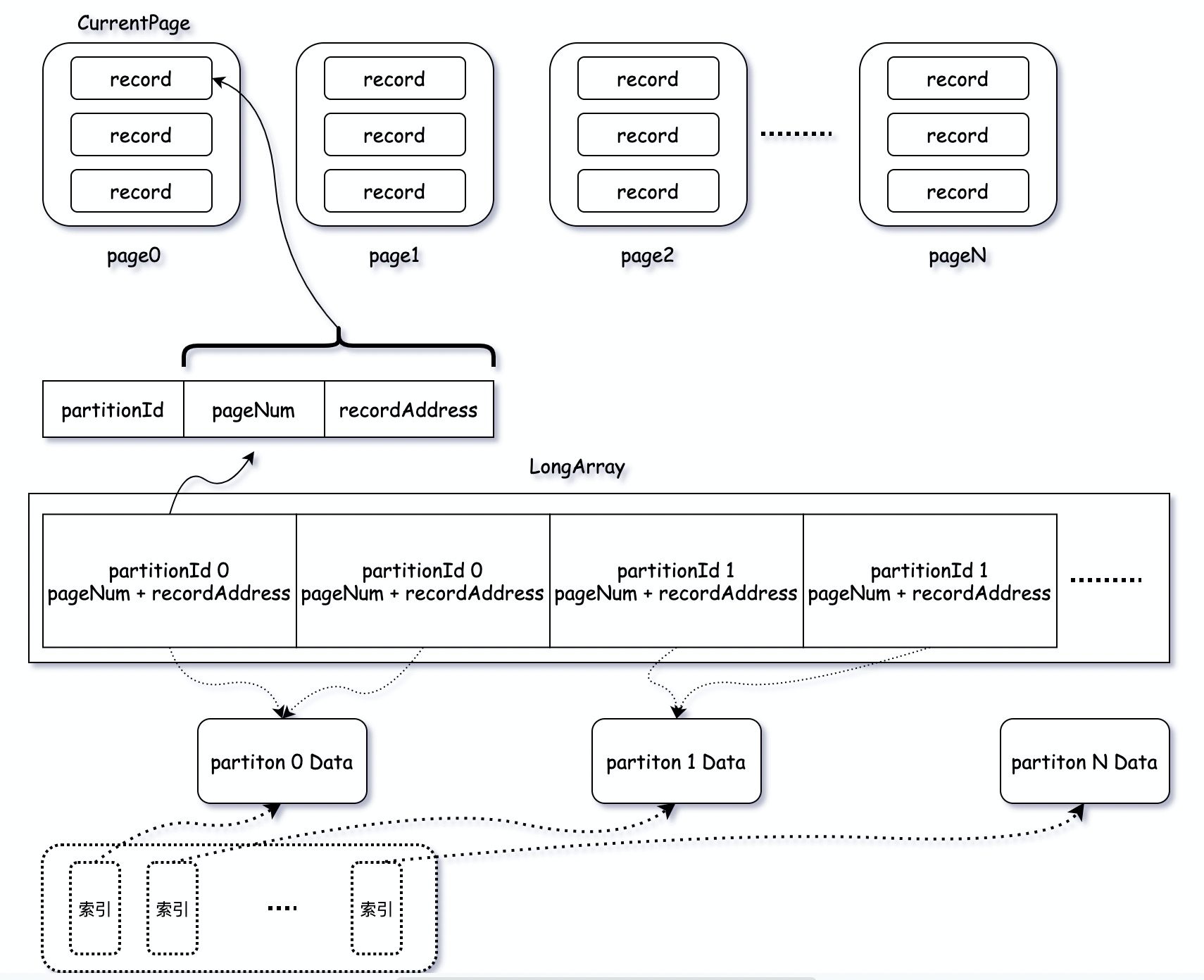
val out = newDataOutputStream(newBufferedOutputStream(newFileOutputStream(indexTmp))) Utils.tryWithSafeFinally { // We take in lengths of each block, need to convert it to offsets. var offset = 0L // 第一位为占位符,0 out.writeLong(offset) // 遍历partition数组,lengths = 各个分区,shuffle文件的长度 for (length <- lengths) {
/** Read the combined key-values for this reduce task */ overridedefread(): Iterator[Product2[K, C]] = { /** * 初始化后会调用 ShuffleBlockFetcherIterator.initialize 方法 * 1、local block 与 Remote block进行分类 * 2、批量发送请求远端block * 3、获取local block */ val wrappedStreams = newShuffleBlockFetcherIterator( context, blockManager.shuffleClient, blockManager, mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition), serializerManager.wrapStream, // Note: we use getSizeAsMb when no suffix is provided for backwards compatibility SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024, SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue), SparkEnv.get.conf.get(config.REDUCER_MAX_BLOCKS_IN_FLIGHT_PER_ADDRESS), SparkEnv.get.conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM), SparkEnv.get.conf.getBoolean("spark.shuffle.detectCorrupt", true))
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) => serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator }
// Update the context task metrics for each record read. val readMetrics = context.taskMetrics.createTempShuffleReadMetrics() val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]]( recordIter.map { record => readMetrics.incRecordsRead(1) record }, context.taskMetrics().mergeShuffleReadMetrics())
val interruptibleIter = newInterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) { if (dep.mapSideCombine) { // 如果指定了聚合函数且允许在map端进行合并,在reduce端再次合并 val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]] dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context) } else { // 如果指定了聚合函数但不允许在map端进行合并,则在reduce端合并 val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]] dep.aggregator.get.combineValuesByKey(keyValuesIterator, context) } } else { interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]] }
// ExternalSorter 排序 val resultIter = dep.keyOrdering match { caseSome(keyOrd: Ordering[K]) => // Create an ExternalSorter to sort the data. val sorter = newExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer) sorter.insertAll(aggregatedIter) context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled) context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled) context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes) // Use completion callback to stop sorter if task was finished/cancelled. context.addTaskCompletionListener[Unit](_ => { sorter.stop() }) CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop()) caseNone => aggregatedIter }
resultIter match { case _: InterruptibleIterator[Product2[K, C]] => resultIter case _ => // Use another interruptible iterator here to support task cancellation as aggregator // or(and) sorter may have consumed previous interruptible iterator. newInterruptibleIterator[Product2[K, C]](context, resultIter) } }