Spark Sql
Spark SQL
Analysis
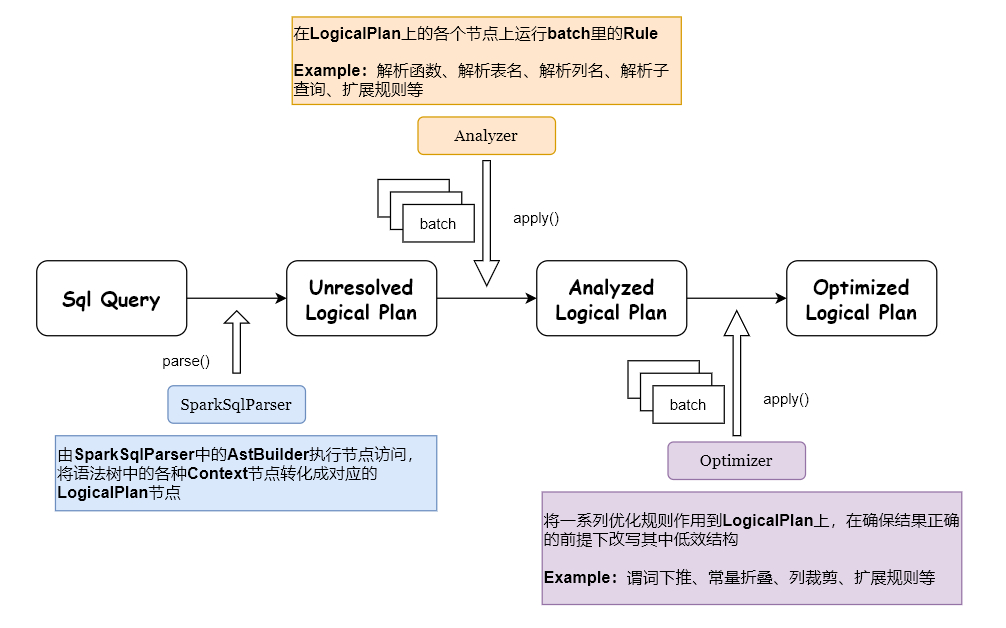
从SQL或者DataFrame API中解析得到抽象语法树,依据catalog元数据校验语法树(表名、列名,或列类型),将Unresolved Logical Plan解析成Resolved Logical Plan
多个性质类似的Rule组成一个Batch,多个Batch构成一个Batchs,这些batches会由RuleExecutor执行,先按一个一个Batch顺序执行,然后对Batch里面的每个Rule顺序执行。每个Batch会执行一次会多次。
Logical Optimizations
基于规则优化,其中包含谓词下推、列裁剪、常亮折叠等。利用Rule(规则)将Resolved Logical Plan解析成Optimized Logical Plan,同样是由RuleExecutor执行
Physical Planning
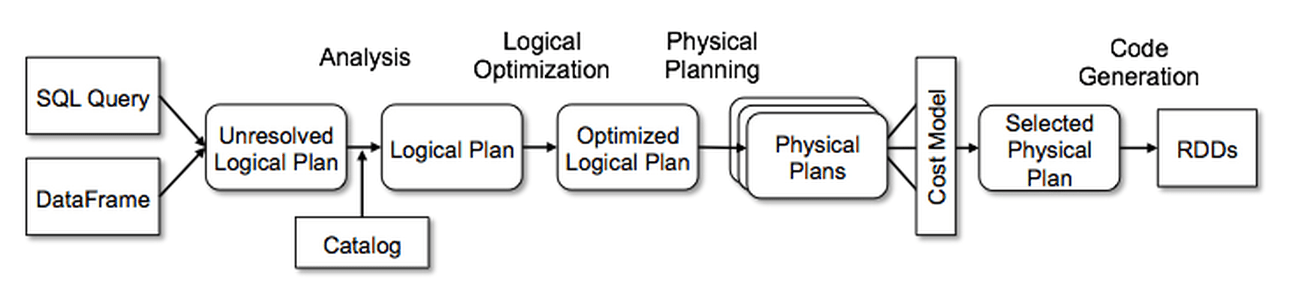
前面的Logical Plan不能被Spark执行,这个过程是把Logical Plan转换成多个Physical Plan(物理计划),然后利用Cost Mode(代价模型)选择最佳的执行计划;
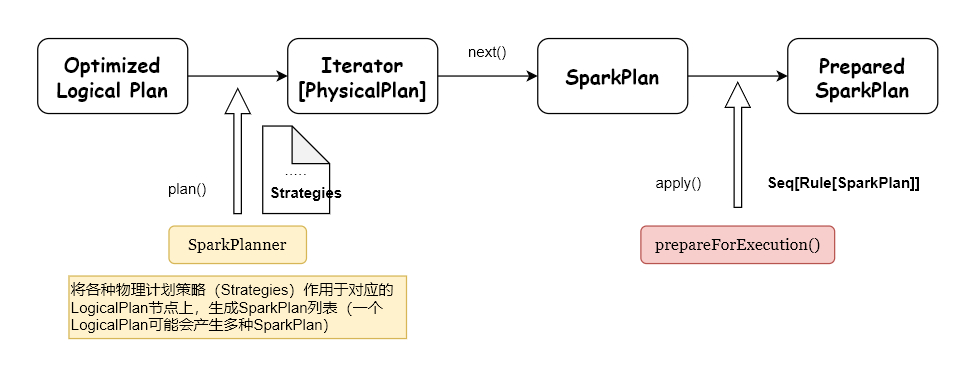
和前面的逻辑计划绑定和优化不一样,这里使用Strategy(策略),而前面介绍的逻辑计划绑定和优化经过transform动作之后,树的类型没有改变,也就是说:Expression 经过 transformations 之后得到的还是 Expression ;Logical Plan 经过 Transformations 之后得到的还是Logical Plan。而到了这个阶段,经过 Transformations 动作之后,树的类型改变了,由Logical Plan转换成Physical Plan了。
一个Logical Plan(逻辑计划)经过一系列的策略处理之后,得到多个物理计划,物理计划在Spark是由SparkPlan实现的。多个Physical Plan再经过Cost Model(代价模型,CBO)得到选择后的物理计划(Selected Physical Plan)
CBO
估算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。
Cost = rows * weight + size * (1 - weight)
- rows:记录行数代表了 CPU 代价
- size:代表了 IO 代价
- spark.sql.cbo.joinReorder.card.weight
LogicalPlan统计信息
LogicalPlanStats以trait的方式在每个LogicalPlan中实现
1 | /** |
如果开启CBO,在Optimize阶段,会通过收集的表信息对InnerJoin sql进行优化,如下图: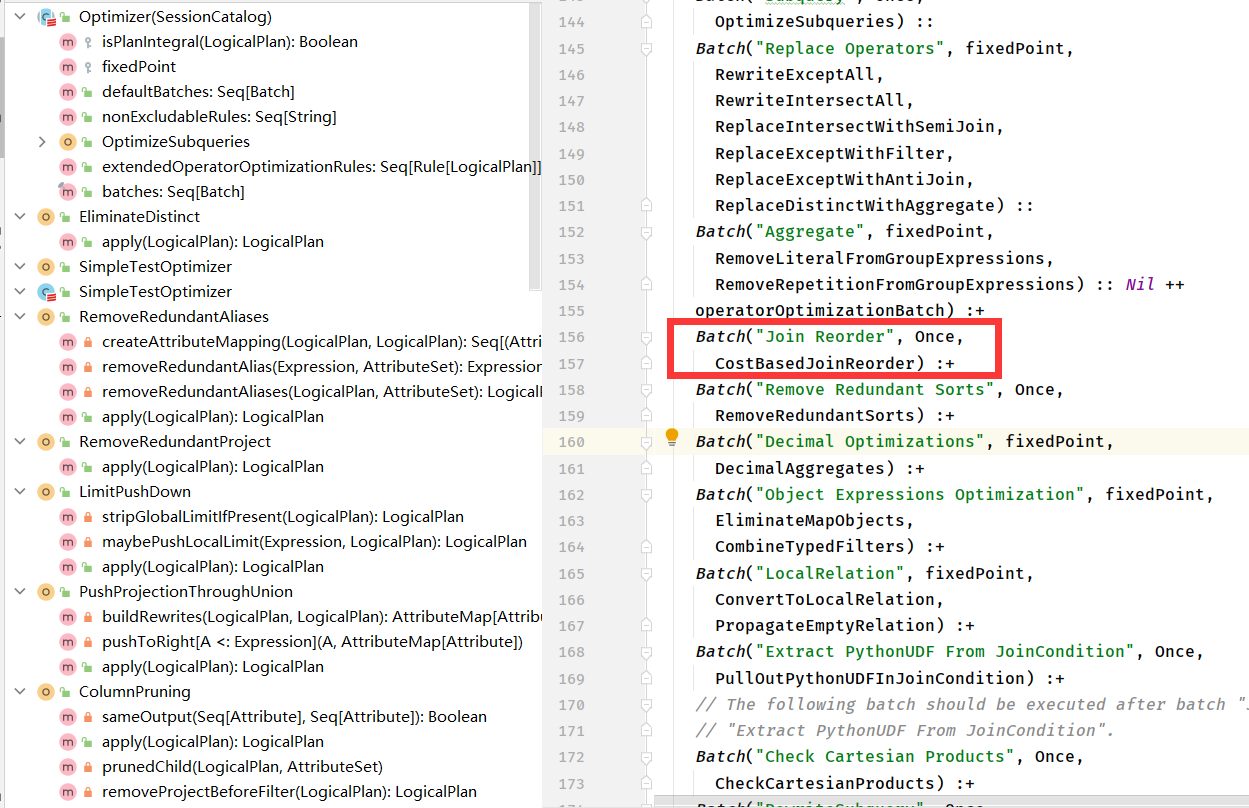
Code Generation
生成java字节码
前面生成的Physical Plan还不能直接交给Spark执行,Spark最后仍然会用一些Rule对SparkPlan进行处理,如下:
QueryExecution
1 | /** A sequence of rules that will be applied in order to the physical plan before execution. */ |
Join Cardinality(基数)
Inner Join : num(A IJ B) = num(A)*num(B)/max(distinct(A.k),distinct(B.k))
Left-Outer Join : num(A LOJ B) = max(num(A IJ B),num(A))
Right-Outer Join : num(A ROJ B) = max(num(A IJ B),num(B))
Full-Outer Join : num(A FOJ B) = num(A LOJ B) + num(A ROJ B) - num(A IJ B)
cost = weight * cardinality + (1.0 - weight) * size
https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
https://databricks.com/blog/2017/08/31/cost-based-optimizer-in-apache-spark-2-2.html
Spark Join
BroadcastJoin
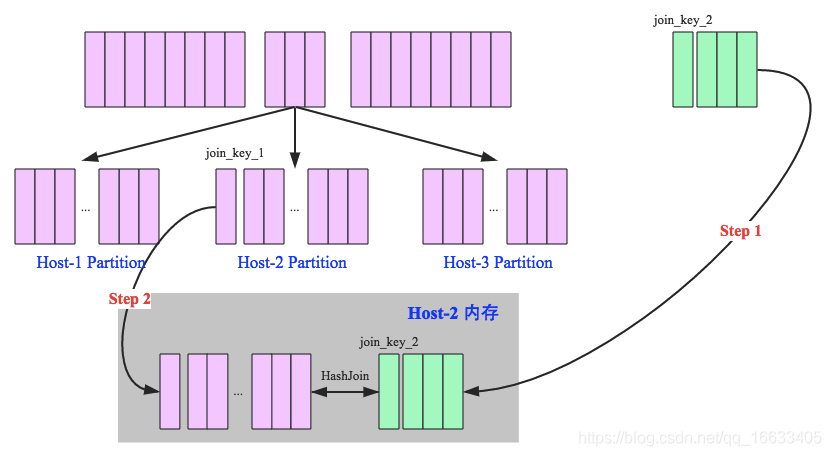
匹配条件
- 等值连接
- 是否有提示(hit)
- 匹配join类型
- 表大小是否小于阈值
执行步骤
- 将小表先拉到driver端,然后在广播到所有executor
spark.sql.autoBroadcastJoinThreshold(默认值为10M)
将broadcat的数据逐行hash,存储到BytesToBytesMap,遍历stream表,逐行取出hash匹配,找出符合条件的数据
Shuffle Hash Join
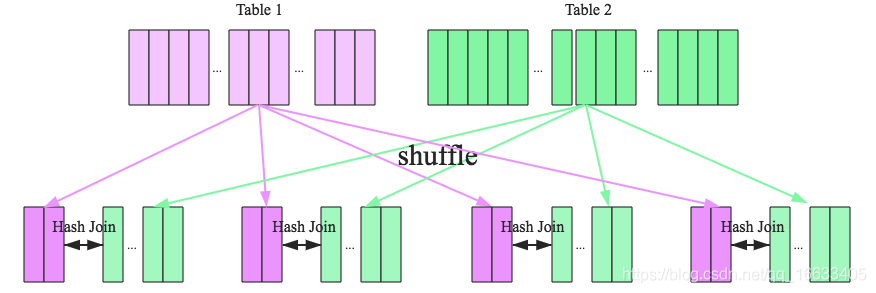
匹配条件
- 等值连接
- 是否优先执行SMJ(SparkConf配置) && 满足join类型 && 表大小 < bhj阈值 * 默认shuffle分区数(200) && 小表大小 * 3 <= 大表大小
||leftkey的类型不能被排序
执行步骤
- shuffle:先对join的key分区,将相同的key分布到同一节点
- hash join:对每个分区中的数据进行join操作,现将小表分区构造一张Hash表(HashedRelation),然后根据大表分区中的记录的key值进行匹配
SMJ
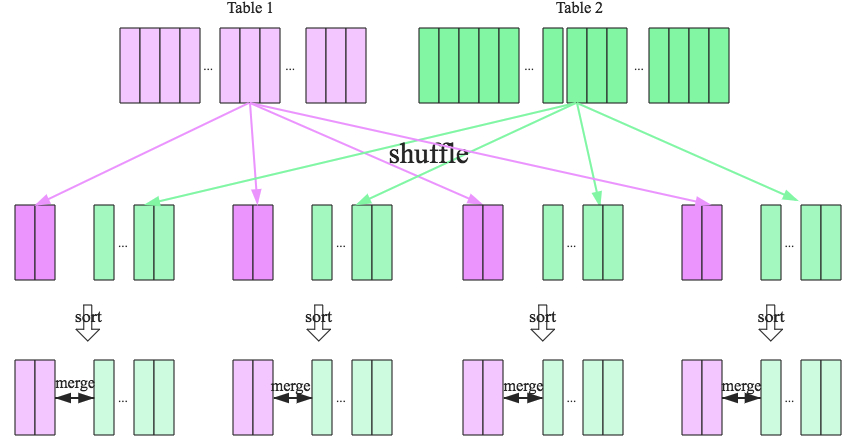
匹配条件
- 等值连接
- leftkey的类型能被排序
执行步骤
- shuffle:先对join的key分区,将相同的key分布到同一节点
- sort:每个分区的两个表排序
- merge:排号序的两张表join,分别遍历两个有序表,遇到相同的key就merge输出(如果右表key大于左表,则左表继续往下遍历;反之右表往下遍历,直至两表key相等,合并结果)
Spark 连接 Hive
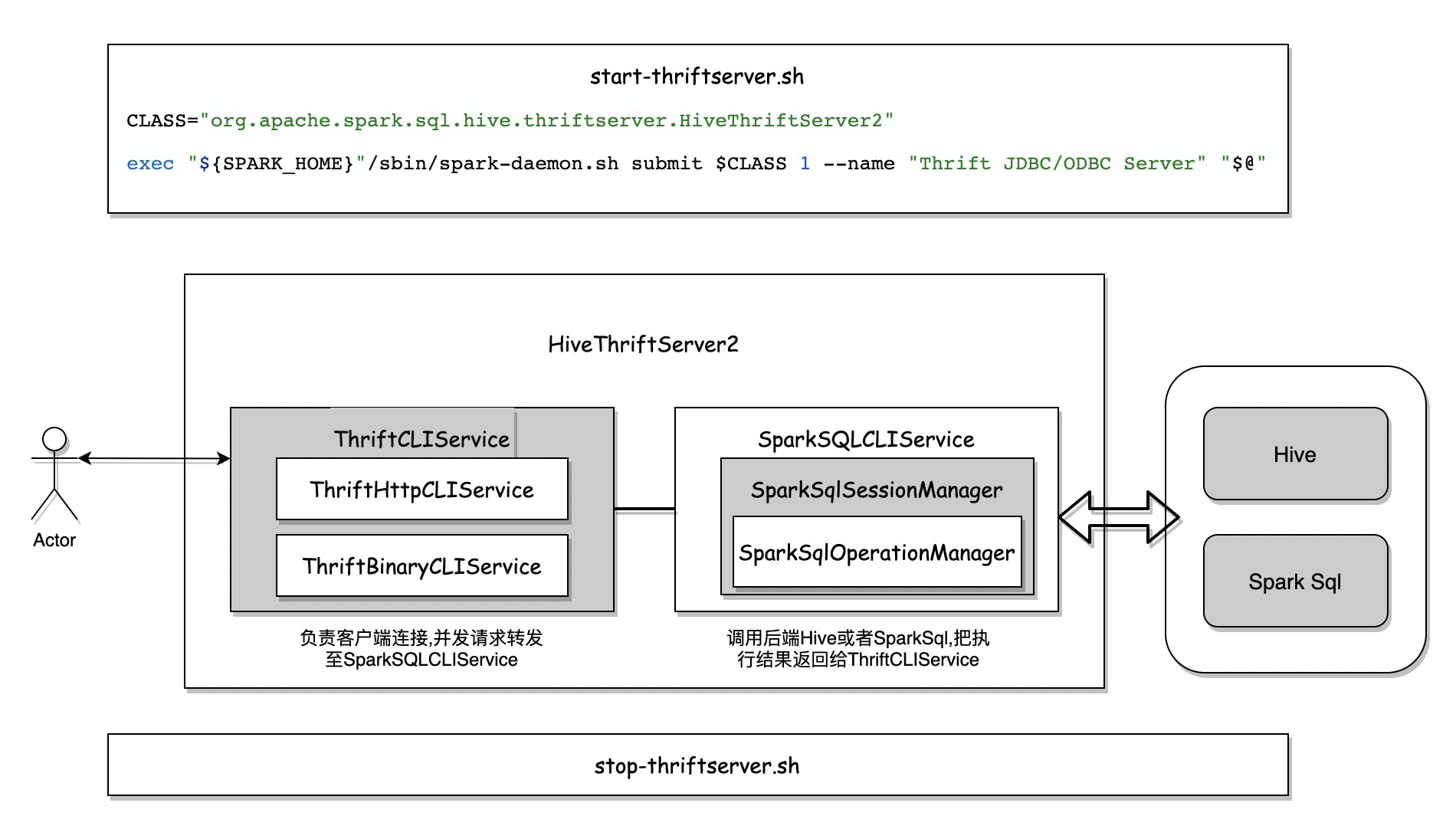
最后sql的执行由SparkSQLOperationManager中创建的SparkExecuteStatementOperation执行并返回结果
HiveThriftServer2启动构建对象
谓词下推源码
1 | // PushDownPredicate |










