voidclose(); // Get a table factory instance that can convert catalog tables in this catalog // to sources or sinks. Null can be returned if table factory isn’t provided, // in which case, the current discovery mechanism will be used. Optional<TableFactory> getTableFactory();
List<String> listDatabases();
CatalogDatabase getDatabase(String databaseName);
/** * List table names under the given database. Throw an exception if database isn’t * found. */
List<String> listTables(String databaseName); /** * List view names under the given database. Throw an exception if database isn’t * found. */ List<String> listViews(String databaseName);
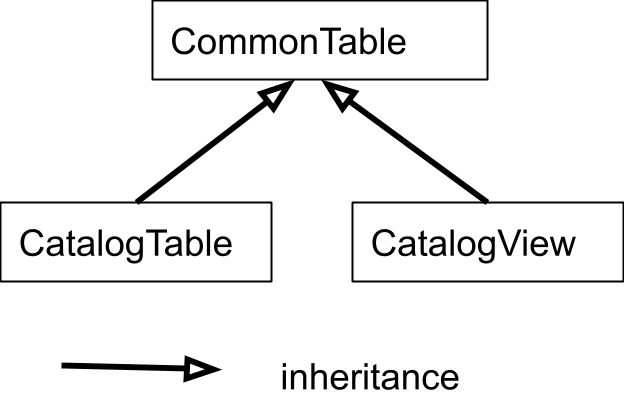
// getTable() can return view as well. CommonTable getTable(ObjectPath tableOrViewName);
/** * List function names under the given database. Throw an exception if * database isn’t found. */ List<String> listFunctions(String databaseName); CatalogFunction getFunction(ObjectPath functionName); }
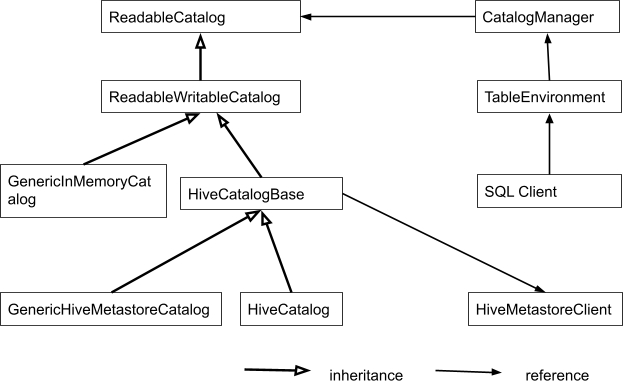
// The catalog to hold all registered and translated tables // We disable caching here to prevent side effects private CalciteSchema internalSchema = CalciteSchema.createRootSchema(true, false);
private SchemaPlus rootSchema = internalSchema.plus(); // A list of named catalogs. private Map<String, ReadableCatalog> catalogs;
// The name of the default catalog private String defaultCatalog = null; publicCatalogManager(Map<String, ReadableCatalog> catalogs, String defaultCatalog){ // make sure that defaultCatalog is in catalogs.keySet(). this.catalogs = catalogs; this.defaultCatalog = defaultCatalog; } publicvoidregisterCatalog(String catalogName, ReadableCatalog catalog){ catalogs.put(catalogName, catalog); } public ReadableCatalog getCatalog(String catalogName){ return catalogs.get(catalogName); }
public Set<String> getCatalogs(){ returnthis.catalogs.keySet(); }
abstract class TableEnvironment(val config: TableConfig){
private val catalogManager:CatalogManager; // This is an existing class with only argument type change def registerCatalog(name: String, catalog: ReadableCatalog): Unit // Set the default catalog def setDefaultCatalog(catName: String); // Set the default database Def setDefaultDatabase(catName: String, databaseName: String): unit }
// this one is existing one, which will be deprecated. @Deprecated StreamTableSource createStreamTableSource(Map<String, String> properties); // This one is new with default implementation. Default StreamTableSource createStreamTableSource(CatalogTable table){ return createStreamTableSource( TableFactoryUtils.convertToProperties(table) ); } }
// this one is existing one StreamTableSink createStreamSinkSource(Map<String, String> properties); // This one is new. Default StreamTableSink createStreamSinkSource(CatalogTable table){ return createStreamTableSink( TableFactoryUtils.convertToProperties(table) ); } }
Interface BatchTableSourceFactory extends TableFactory { // this one is existing one BatchTableSource createBatchTableSource(Map<String, String> properties); // This one is new. Default BatchTableSource createBatchTableSource(CatalogTable table){ return createBatchTableSource( TableFactoryUtils.convertToProperties(table) ); } }
Interface BatchTableSinkFactory extends TableFactory { // this one is existing one BatchTableSink createBatchTableSink(Map<String, String> properties); // This one is new. BatchTableSink createBatchTableSink(CatalogTable table){ return createBatchTableSink( TableFactoryUtils.convertToProperties(table) ); }
/** * Batch only for now. */ Public classHiveTableFactoryimplementsBatchTableSourceFactory, BatchTableSinkFactory{
Map<String, String> requiredContext(){ // return an empty map to indicate that auto discovery is not needed. returnnew HashMap<>(); }
List<String> supportedProperties(){ // Return an empty list to indicate that no check is needed. Return new ArrayList<>(); }
BatchTableSource createBatchTableSource(Map<String, String> properties){ // convert properties to catalogtable and call the other version of this method. // It’s fine not to support this method. } BatchTableSource createBatchTableSink(Map<String, String> properties){ // convert properties to catalogtable and call the other version of this method. // It’s fine not to support this method. }
BatchTableSource createBatchTableSource(CatalogTable table){ Assert (table instanceof HiveTable); HiveTable hiveTable = (HiveTable)table; // create a table source based on HiveTable // This is specific implementation for Hive tables. } BatchTableSource createBatchTableSink(CatalogTable table){ Assert (table instanceof HiveTable); HiveTable hiveTable = (HiveTable)table; // create a table sink based on HiveTable // This is specific implementation for Hive tables. } }
我们在Flink SQL中引入了默认数据库概念。这对应于SQL“使用xxx”,其中将架构(数据库)设置为当前架构,而没有数据库/架构前缀的任何表都引用默认架构。由于Flink具有多个目录,因此语法将为“ use cat1.db1”,其中cat1将是默认目录,而db1将是默认数据库。给定一个表名,目录管理器必须将其解析为全名,以便正确识别该表。